本文尝试以 GPU 漏洞为引介绍围绕 GPU 驱动这一攻击面,安全研究人员对内核漏洞利用技术做的一些探索。
背景介绍
目前移动 SOC 平台上由多个硬件模块组成,常见的硬件模块有:CPU、GPU、Modem基带处理器、ISP(图像处理器)等,这些硬件模块通过硬件总线互联,协同完成任务。
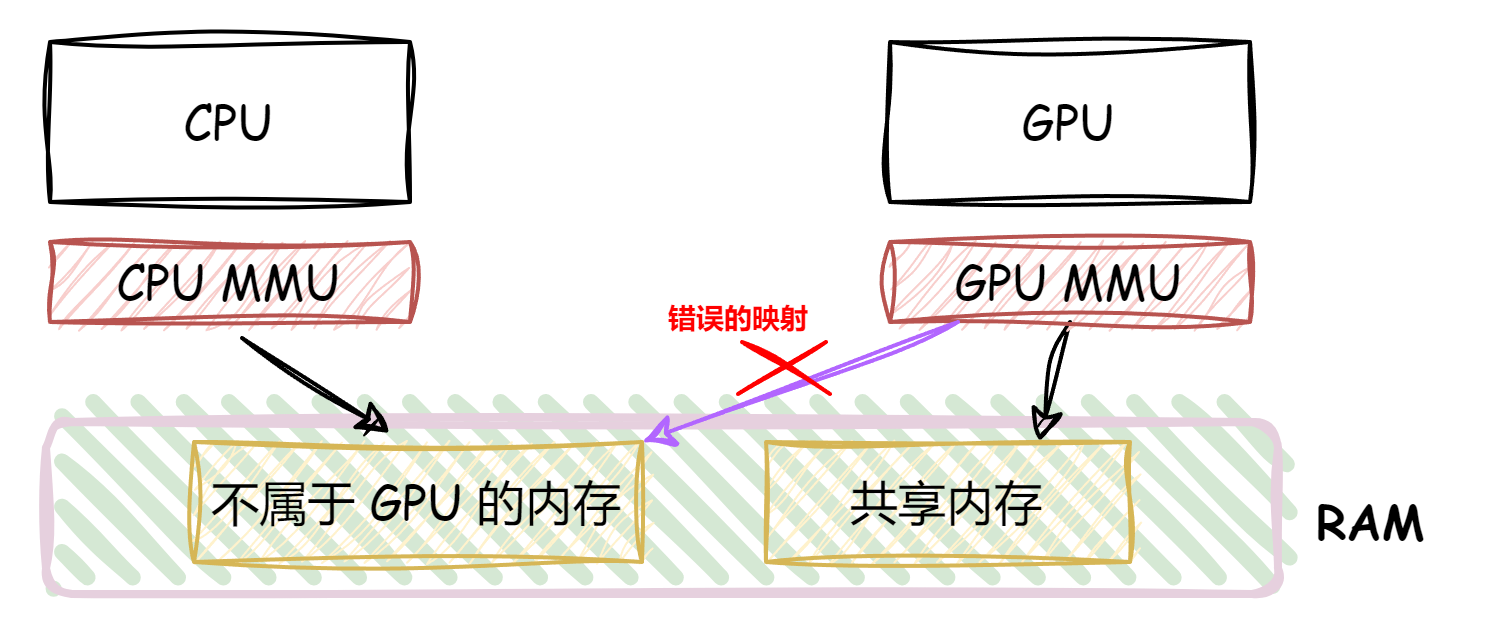
对于 GPU 驱动漏洞研究来说,我们需要关注的一个关键特性是 GPU 和 CPU 共用同一块 RAM。 在 CPU 侧操作系统通过管理 CPU MMU 的页表来实现虚拟地址到物理地址的映射

GPU 也有自己的 MMU,不过 GPU 的页表由 CPU 内核中的 GPU 驱动管理,从而限制 GPU 能够访问的物理地址范围。

在实际的业务使用中,一般是 CPU 侧分配一段物理内存,然后映射给 GPU , GPU 从共享内存中取出数据完成计算、渲染后再将结果写回共享内存,从而完成 GPU 与 GPU 之间的交互。对于 GPU 驱动安全研究来说,特殊的攻击面在于由于其需要维护 GPU 页表,这个过程比较复杂,涉及到内核中的各个模块的配合,非常容易出现问题,历史上也出现了多个由于 GPU 页表管理失误导致的安全漏洞
以 ARM Mali 驱动为例,这几年出现的几个比较有代表性的漏洞如下:
| 漏洞 | 类型 | 漏洞原语 |
|---|
| CVE-2021-39793 | 页权限错误 | 篡改 只读映射到用户进程的物理页 |
| CVE-2021-28664 | 页权限错误 | 篡改 只读映射到用户进程的物理页 |
| CVE-2021-28663 | GPU MMU 操作异常 | 物理页 UAF |
| CVE-2023-4211 | 条件竞争 UAF | SLUB 对象 UAF |
| CVE-2023-48409 | 整数溢出 | 堆溢出 |
| CVE-2023-26083 | 内核地址泄露 | 内核地址泄露 |
| CVE-2022-46395 | 条件竞争 UAF | 物理页 UAF |
其中前 3 个漏洞是管理 GPU 页表映射时的漏洞,后面几个就是常规驱动漏洞类型
CVE-2021-28664
分析代码下载:https://armkeil.blob.core.windows.net/developer/Files/downloads/mali-drivers/kernel/mali-bifrost-gpu/BX304L01B-SW-99002-r19p0-01rel0.tar
先以最简单的漏洞开始讲起,这个漏洞算是 Mali 第一个出名的漏洞了,同期出道的还有 CVE-2021-28664,这个漏洞是由 Project Zero 捕获的在野利用,该漏洞的 Patch 如下
static struct kbase_va_region *kbase_mem_from_user_buffer(
struct kbase_context *kctx, unsigned long address,
unsigned long size, u64 *va_pages, u64 *flags)
{
[...]
+ int write;
[...]
+ write = reg->flags & (KBASE_REG_CPU_WR | KBASE_REG_GPU_WR);
+
#if KERNEL_VERSION(4, 6, 0) > LINUX_VERSION_CODE
faulted_pages = get_user_pages(current, current->mm, address, *va_pages,
#if KERNEL_VERSION(4, 4, 168) <= LINUX_VERSION_CODE && \
KERNEL_VERSION(4, 5, 0) > LINUX_VERSION_CODE
- reg->flags & KBASE_REG_CPU_WR ? FOLL_WRITE : 0,
- pages, NULL);
+ write ? FOLL_WRITE : 0, pages, NULL);
#else
- reg->flags & KBASE_REG_CPU_WR, 0, pages, NULL);
+ write, 0, pages, NULL);
#endif
#elif KERNEL_VERSION(4, 9, 0) > LINUX_VERSION_CODE
faulted_pages = get_user_pages(address, *va_pages,
- reg->flags & KBASE_REG_CPU_WR, 0, pages, NULL);
+ write, 0, pages, NULL);
#else
faulted_pages = get_user_pages(address, *va_pages,
- reg->flags & KBASE_REG_CPU_WR ? FOLL_WRITE : 0,
- pages, NULL);
+ write ? FOLL_WRITE : 0, pages, NULL);
#endif
Patch 的关键点在于将 get_user_pages 参数中的 reg->flags & KBASE_REG_CPU_WR 换成了 reg->flags & (KBASE_REG_CPU_WR | KBASE_REG_GPU_WR) ,这两个标记的作用如下:
- KBASE_REG_CPU_WR:表示 reg 能够已写权限映射到用户态进程
- KBASE_REG_GPU_WR: 表示 reg 能够已写权限映射到 GPU
reg 的类型为 struct kbase_va_region , MALI 驱动中使用 kbase_va_region 管理物理内存,包括物理内存的申请/释放、GPU/CPU 页表映射管理等。

图中的关键要素如下:
- kbase_va_region 中 cpu_alloc 和 gpu_alloc 指向 kbase_mem_phy_alloc ,表示该 reg 拥有的物理页,且大部分场景下 cpu_alloc = gpu_alloc
- kbase_va_region 的 flags 字段控制驱动映射 reg 时的权限,假如 flags 为 KBASE_REG_CPU_WR 表示该 reg 能够被 CPU 映射为可写权限,如果没有该 flag 则不允许将 reg 以可写模式映射到 CPU 进程,确保无法进程修改这些物理页
核心观点:驱动利用 kbase_va_region 表示一组物理内存,这组物理内存可以被 CPU 上的用户进程和 GPU 分别映射,映射的权限由 reg->flags 字段控制.
回到漏洞本身,其调用路径中的关键代码如下:
kbase_api_mem_import
u64 flags = import->in.flags;
kbase_mem_import(kctx, import->in.type, u64_to_user_ptr(import->in.phandle), import->in.padding, &import->out.gpu_va, &import->out.va_pages, &flags);
copy_from_user(&user_buffer, phandle
uptr = u64_to_user_ptr(user_buffer.ptr);
kbase_mem_from_user_buffer(kctx, (unsigned long)uptr, user_buffer.length, va_pages, flags)
- struct kbase_va_region *reg = kbase_alloc_free_region(rbtree, 0, *va_pages, zone);
- kbase_update_region_flags(kctx, reg, *flags) // 根据用户态提供的 flags 设置 reg->flags
- faulted_pages = get_user_pages(address, *va_pages, reg->flags & KBASE_REG_GPU_WR, 0, pages, NULL);
漏洞在于传递 get_user_pages 参数是只考虑了 KBASE_REG_GPU_WR 情况,没有考虑 KBASE_REG_CPU_WR,当 reg->flags 为 KBASE_REG_CPU_WR 时 get_user_pages 的第三个参数为 0
long get_user_pages(unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
struct vm_area_struct **vmas)
{
return __get_user_pages_locked(current, current->mm, start, nr_pages,
pages, vmas, NULL, false,
gup_flags | FOLL_TOUCH);
}
get_user_pages 的作用的是根据用户进程提供的 va (start)遍历进程页表,返回的是 va 对应物理地址对应的 page 结构体指针,结果保存到 pages 数组中。

即根据 task_struct->mm 找到进程页表,遍历页表获取物理地址
其中如果 gup_flags 为 1,表示获取 va 对应 page 后会写入 page 对应的物理页,然后在 get_user_pages 内部需要对只读页面和 COW 页面做额外处理,避免这些特殊 va 对应的物理页被修改导致非预期行为。
- 如果 vma 为只读,API 返回错误码
- VA 的映射为 COW 页,在 API 内会完成写时拷贝,并返回新分配的 page

当 gup_flags 为 0 时则直接返回页表遍历的结果(P0)
对于这个漏洞而言,我们可以创建一个 reg->flags 为 KBASE_REG_CPU_WR 的 kbase_va_region,再导入页面时就可以获取进程中任意 va 对应 page 到 kbase_va_region,最后再将其以可写权限映射到用户态进程,这样就可以实现篡改进程中任意只读映射对应的物理页。
这一原语要进一步利用需要依赖操作系统的机制,首先介绍最简单的一种利用方式,Linux 内核在处理磁盘中的文件系统时,会对从磁盘中读取的物理页做缓存来加速文件访问的性能,同时减少重复文件物理页,减少开销
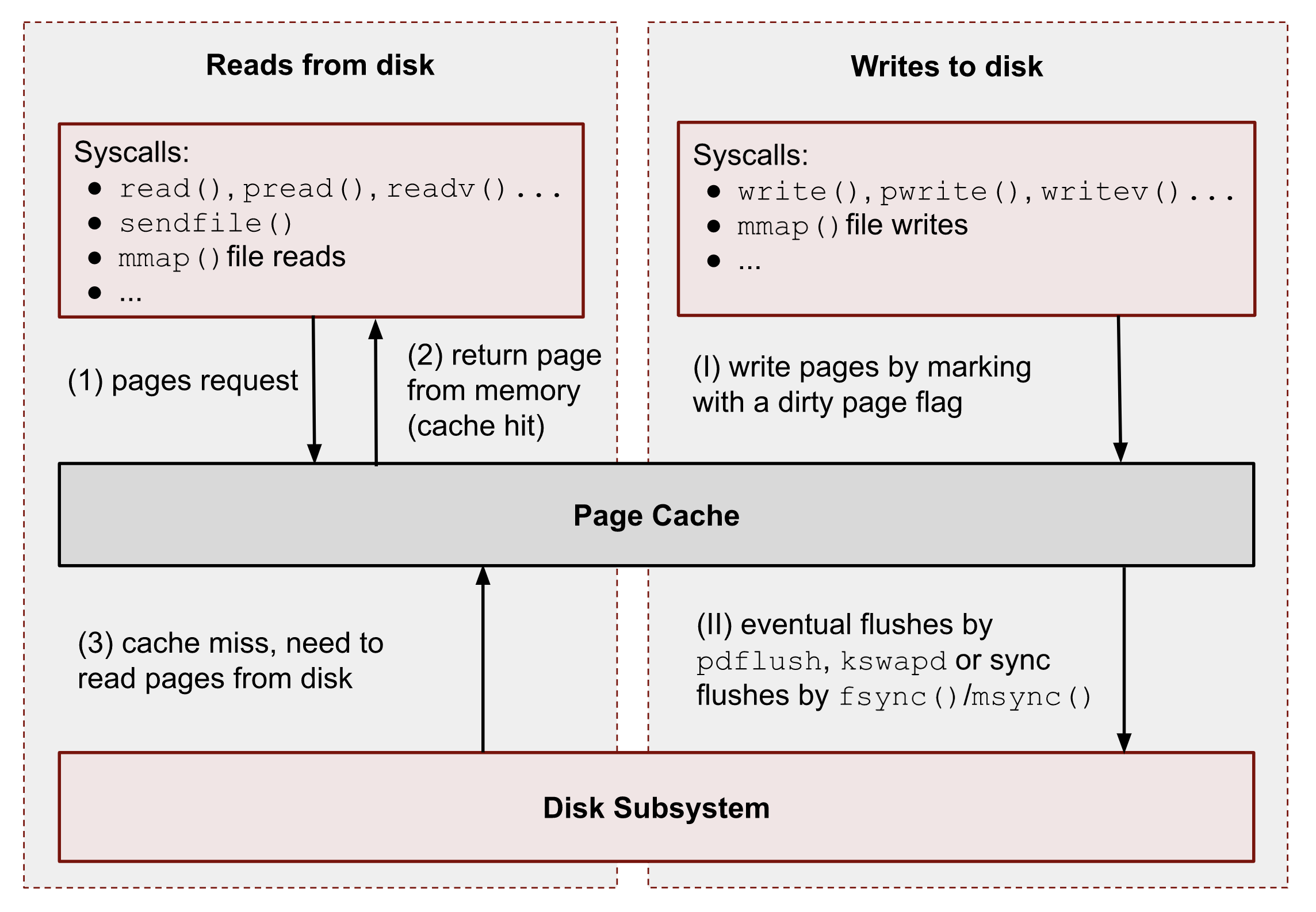
如果所示:
- 当进程尝试读取物理页时,比如只读权限 mmap ,内核会搜索 page cache 如果找到就直接返回,否则就从磁盘中加载物理页到 Page Cache 中,然后返回
- 如果是写则会有对应的 flush cache 机制
具体来说,当两个进程同时以只读权限 mmap libc.so 文件时,这两个进程的 VA 会指向同一个物理页
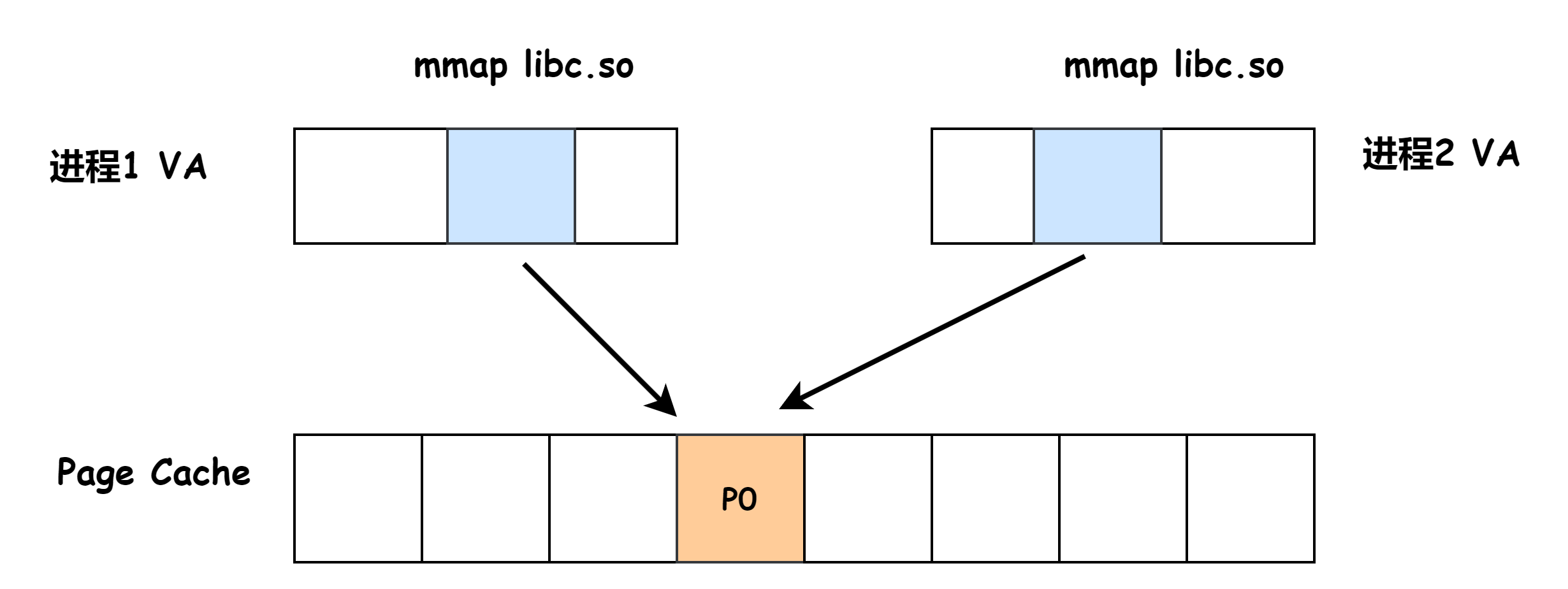
这样当我们利用漏洞修改 Page Cache 中的物理页后,其他进程也会受到影响,因为都是映射的同一块物理地址,因此攻击思路就来了:
- 只读映射 libc.so 利用漏洞篡改其在 Page Cache 中物理页,在其中注入 shellcode,等高权限进程调用时就能提权
- 类似的手法修改 /etc/passwd 完成提权
除了修改文件系统的 Page Cache 外,在 Android 平台上还有一个非常好的目标,binder 驱动会往用户态进程映射只读 page,里面的数据结构为 flat_binder_object,binder_transaction_buffer_release 里面会使用 flat_binder_object->handle,相关代码如下:

首先通过 binder_get_node 查找 node,然后会调用 binder_put_node 减少 node 的引用计数,当 node 引用为0时会释放 node。
由于 flat_binder_object 所在物理页用户态无法修改,所以可以保证这个流程的正确性,当我们只读物理页写漏洞篡改 flat_binder_object->handle 指向另一个 node 时,触发 binder_transaction_buffer_release 就能导致 node 引用计数不平衡
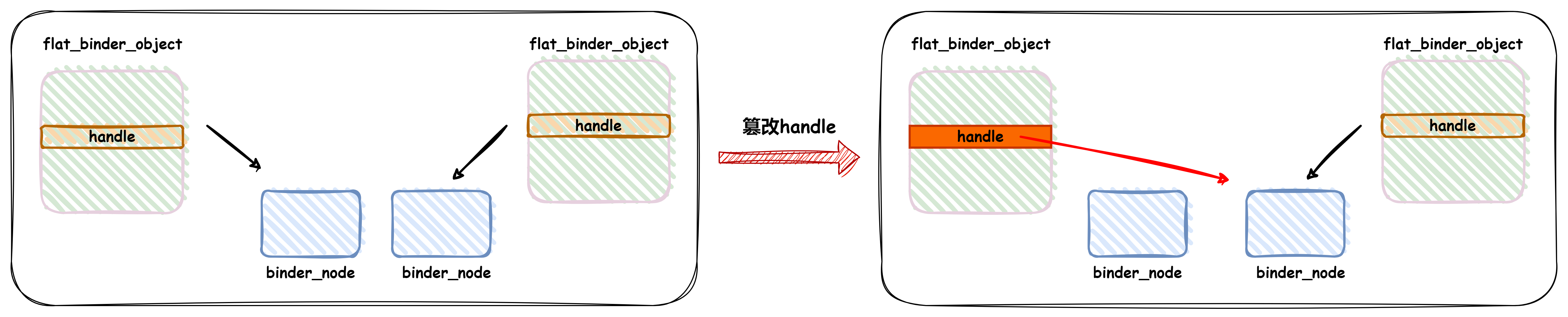
最后可以将漏洞转换为 binder_node 的UAF,然后采用 CVE-2019-2205 的利用方式进行漏洞利用即可。
此外类似的漏洞在 2016 年就已经出现在高通 GPU 驱动中,CVE-2016-2067:

同样的业务场景,也意味着同类型的漏洞也可能会产生
CVE-2021-28663
该漏洞是 Mali 驱动在管理 GPU 物理页映射时导致的物理页 UAF 漏洞,为了能够理解该漏洞,首先需要对 Mali 驱动的相关代码有所了解,上节提到 Mali 使用 kbase_va_region 对象表示物理内存资源,然后 CPU 用户进程 和 GPU 可以按需映射,对物理内存进行访问。

kbase_va_region 的创建位于 kbase_api_mem_alloc 接口,其关键代码如下:
kbase_api_mem_alloc
kbase_mem_alloc(kctx, alloc->in.va_pages, alloc->in.commit_pages, alloc->in.extent, &flags, &gpu_va);
reg = kbase_alloc_free_region(rbtree, 0, va_pages, zone); // 分配reg
kbase_reg_prepare_native(reg, kctx, base_mem_group_id_get(*flags))
- reg->cpu_alloc = kbase_alloc_create(kctx, reg->nr_pages, KBASE_MEM_TYPE_NATIVE, group_id);
- reg->gpu_alloc = kbase_mem_phy_alloc_get(reg->cpu_alloc);
kbase_alloc_phy_pages(reg, va_pages, commit_pages) // 为 reg 分配物理内存
if *flags & BASE_MEM_SAME_VA
- kctx->pending_regions[cookie_nr] = reg;
- cpu_addr = vm_mmap(kctx->filp, 0, va_map, prot, MAP_SHARED, cookie); // 映射物理内存到 GPU 和 CPU 页表
else
kbase_gpu_mmap(kctx, reg, 0, va_pages, 1) // 映射物理内存到 GPU 页表
- 编辑 GPU 页表插入映射
- atomic_inc(&alloc->gpu_mappings); // 增加 gpu_mappings 记录其被 GPU 的引用情况
对于 BASE_MEM_SAME_VA 情况驱动会做特殊处理,SAME_VA 的意思是在映射 reg 时,GPU 和 CPU 的虚拟地址是一样的,这样可能是为了便于数据传递时,之间进行指针传递。

如果没有设置 BASE_MEM_SAME_VA 则会之间将物理内存映射到 GPU,否则就会通过 vm_mmap --> kbase_mmap --> kbasep_reg_mmap 将物理内存以同样的 VA 映射到 GPU 和 CPU 侧。
两者均是使用 kbase_gpu_mmap 将 reg 对应的物理内存映射到 GPU 的页表中.
kbase_va_region 的释放位于 kbase_api_mem_free 接口,其关键代码如下:
kbase_api_mem_free
reg = kbase_region_tracker_find_region_base_address(kctx, gpu_addr);
err = kbase_mem_free_region(kctx, reg);
这个的大体逻辑是先根据 gpu_addr 找到 reg,然后释放 reg 和 reg->xx_alloc 的引用,对于这种复杂的对象管理,可以先按照正常流程分析下对象之间的关系, kbase_va_region 中与生命周期相关的字段如下:

上图表示的是 kbase_api_mem_alloc 创建非 SAME_VA 内存的场景,kbase_gpu_mmap 执行后会对 gpu_mappings 加一,然后通过 kbase_api_mem_free 释放时,会将 kbase_va_region 和 kbase_mem_phy_alloc 的引用计数减成0,从而释放两个对象
如果是 SAME_VA 的情况如下,区别在于 SAME_VA 内存在 kbase_api_mem_alloc 中会调用 vm_mmap 把 reg 同时映射到 CPU 和 GPU 侧,这就需要增加对应的引用计数(va_refcnt、kref、gpu_mappings),然后在 munmap 进程 VA 时,减少对应的引用计数

对驱动的对象管理有大概的认知后,具体看下漏洞相关的两个接口 kbase_api_mem_alias 和 kbase_api_mem_flags_change,分别利用的功能:
- kbase_api_mem_alias:创建别名映射,即新分配一个 reg 与其他已有的 reg 共享 kbase_mem_phy_alloc
- kbase_api_mem_flags_change:释放 kbase_mem_phy_alloc 中的物理页
kbase_api_mem_alias 的关键代码如下:
kbase_mem_alias
- reg = kbase_alloc_free_region(&kctx->reg_rbtree_same, 0, *num_pages, KBASE_REG_ZONE_SAME_VA);
- reg->gpu_alloc = kbase_alloc_create(kctx, 0, KBASE_MEM_TYPE_ALIAS,
- reg->cpu_alloc = kbase_mem_phy_alloc_get(reg->gpu_alloc);
- aliasing_reg = kbase_region_tracker_find_region_base_address( kctx, (ai[i].handle.basep.handle >> PAGE_SHIFT) << PAGE_SHIFT);
- alloc = aliasing_reg->gpu_alloc;
- reg->gpu_alloc->imported.alias.aliased[i].alloc = kbase_mem_phy_alloc_get(alloc);
- kctx->pending_regions[gpu_va] = reg;
主要是增加了 alloc 的引用计数 (kref),然后将其放入 kctx->pending_regions,之后进程再通过 mmap 完成 CPU 和 GPU 映射 (kbase_context_mmap)
if (reg->gpu_alloc->type == KBASE_MEM_TYPE_ALIAS) {
u64 const stride = alloc->imported.alias.stride;
for (i = 0; i < alloc->imported.alias.nents; i++) {
if (alloc->imported.alias.aliased[i].alloc) {
err = kbase_mmu_insert_pages(kctx->kbdev,
&kctx->mmu,
reg->start_pfn + (i * stride),
alloc->imported.alias.aliased[i].alloc->pages + alloc->imported.alias.aliased[i].offset,
alloc->imported.alias.aliased[i].length,
reg->flags & gwt_mask,
kctx->as_nr,
group_id);
kbase_mem_phy_alloc_gpu_mapped(alloc->imported.alias.aliased[i].alloc);
}
}
创建别名映射进程调用 mmap 前后, reg 对象相关引用情况如下:

在 kbase_api_mem_alias 里面增加 aliased[i]->kref 确保其在使用过程中不会被释放,然后 kbase_mmap 映射内存时增加 aliased[i]->gpu_mappings 记录其被 GPU 映射的次数,同时增加 reg->va_refcnt 记录其被 CPU 映射的次数,这个流程是没有问题的,通过引用计数确保 aliased 中的对象不会释放。
问题就出在 kbase_api_mem_flags_change 能在不释放 alloc 时释放其中的物理页:
kbase_api_mem_flags_change 可以利用 kbase_mem_evictable_make 将 gpu_alloc 放到驱动自己管理的链表中(kctx->evict_list)当内核指向 shrink 操作时驱动会释放该链表上挂的所有 gpu_alloc。
kbase_mem_evictable_make
- kbase_mem_shrink_cpu_mapping(kctx, gpu_alloc->reg, 0, gpu_alloc->nents); // 移除 CPU 映射
- list_add(&gpu_alloc->evict_node, &kctx->evict_list); // 加到链表中
shrink 时释放 kbase_mem_phy_alloc 物理页的代码:
kbase_mem_flags_change 在调用 kbase_mem_evictable_make 前会校验 gpu_mappings ,大概意思是如果这个 reg 被 GPU 多次映射了就不能执行物理内存释放操作,但是回到 alias 的流程,在 kbase_api_mem_alias 结束后,aliased 数组中的 gpu_mappings 还是 1
此时调用 kbase_mem_flags_change 将 aliased[i] 放到 kctx->evict_list,此时 alloc->pages 里面的值没有变化
然后再调用 mmap 映射 kbase_mem_alias 创建的 reg 将 aliased[i] 中的物理页(alloc->pages)映射到 GPU 侧,假设为映射的 VA 为 ALIAS_VA
最后触发 shrink 机制,释放 aliased[i] 中的物理页,之后 ALIAS_VA 还指向已经释放的物理页,导致物理页 UAF.
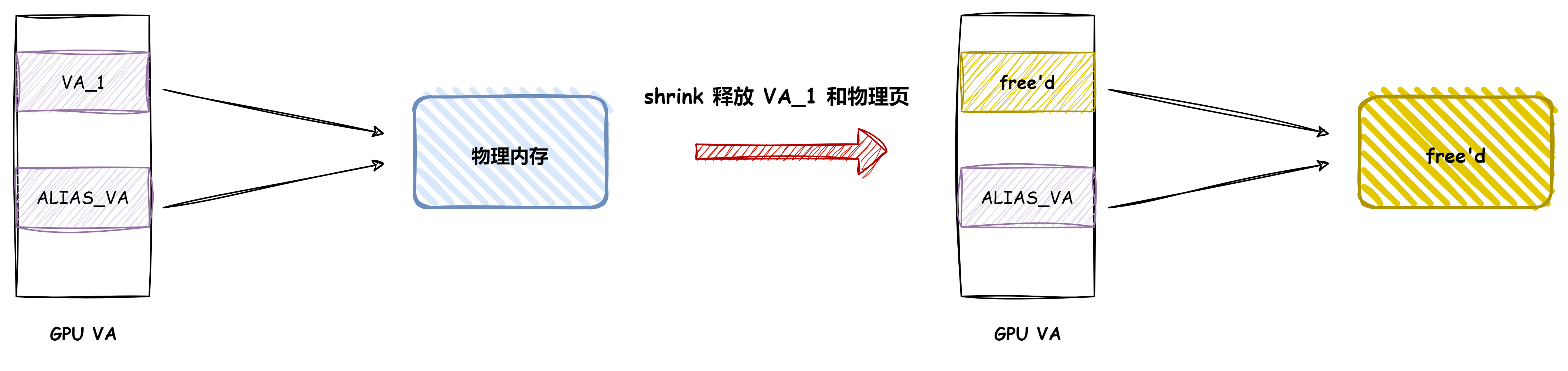
再次回顾漏洞根因,漏洞是驱动在建立 别名映射时对 gpu_mappings 的管理不当,结合 kbase_api_mem_flags_change 释放物理页的逻辑,达成物理页 UAF,这种漏洞的挖掘个人理解需要先分析内存对象(堆、物理内存)的生命周期,然后组合各个 API 的时序看是否会产生非预期行为,重点还是对象的释放、申请、复制等逻辑。
物理页 UAF 的漏洞利用技术目前已经比较成熟,这里列几个常用的方式:
- 篡改进程页表:通过 fork + mmap 大量分配进程页表占位释放的物理页,然后通过 GPU 修改页表实现任意物理内存读写
- 篡改 GPU 页表:通过 GPU 驱动接口分配 GPU 页表占位释放的物理页,然后通过 GPU 修改页表实现任意物理内存读写
- 篡改内核对象:通过喷射内核对象(比如 task_struct、cred)占位,然后 GPU 修改对象实现利用
CVE-2022-46395
前面两个漏洞的利用路径大概是:发现一个新漏洞,挖掘一种新漏洞利用方式完成利用,本节这个漏洞则是将漏洞转换为 CVE-2021-28663 ,因为 28663 的能力确实太强大了,物理页 UAF 的利用简单、直接,目前堆上的漏洞利用也逐步往物理页UAF 转换(Dirty Pagetable)
漏洞是一个条件竞争漏洞,kbase_vmap_prot 后其他线程可以释放 mapped_evt 对应的物理页
static int kbasep_write_soft_event_status(
struct kbase_context *kctx, u64 evt, unsigned char new_status)
{
...
mapped_evt = kbase_vmap_prot(kctx, evt, sizeof(*mapped_evt),
KBASE_REG_CPU_WR, &map);
if (!mapped_evt)
return -EFAULT;
*mapped_evt = new_status;
kbase_vunmap(kctx, &map);
return 0;
}
为了扩大 race 的时间窗,作者利用 timerfd 时钟中断技术
migrate_to_cpu(0);
int tfd = timerfd_create(CLOCK_MONOTONIC, 0);
int epfds[NR_EPFDS];
for (int i=0; i<NR_EPFDS; i++)
epfds[i] = epoll_create1(0);
for (int i=0; i<NR_EPFDS; i++) {
struct epoll_event ev = { .events = EPOLLIN };
epoll_ctl(epfd[i], EPOLL_CTL_ADD, fd, &ev);
}
timerfd_settime(tfd, TFD_TIMER_ABSTIME, ...);
ioctl(mali_fd, KBASE_IOCTL_SOFT_EVENT_UPDATE,...);
大致思路就是在 kbase_vmap_prot 和 *mapped_evt 之间出发时钟中断,从而扩大时间窗,在两步之间释放 mapped_evt 对应的物理页,就能够达到物理页 UAF 的能力。
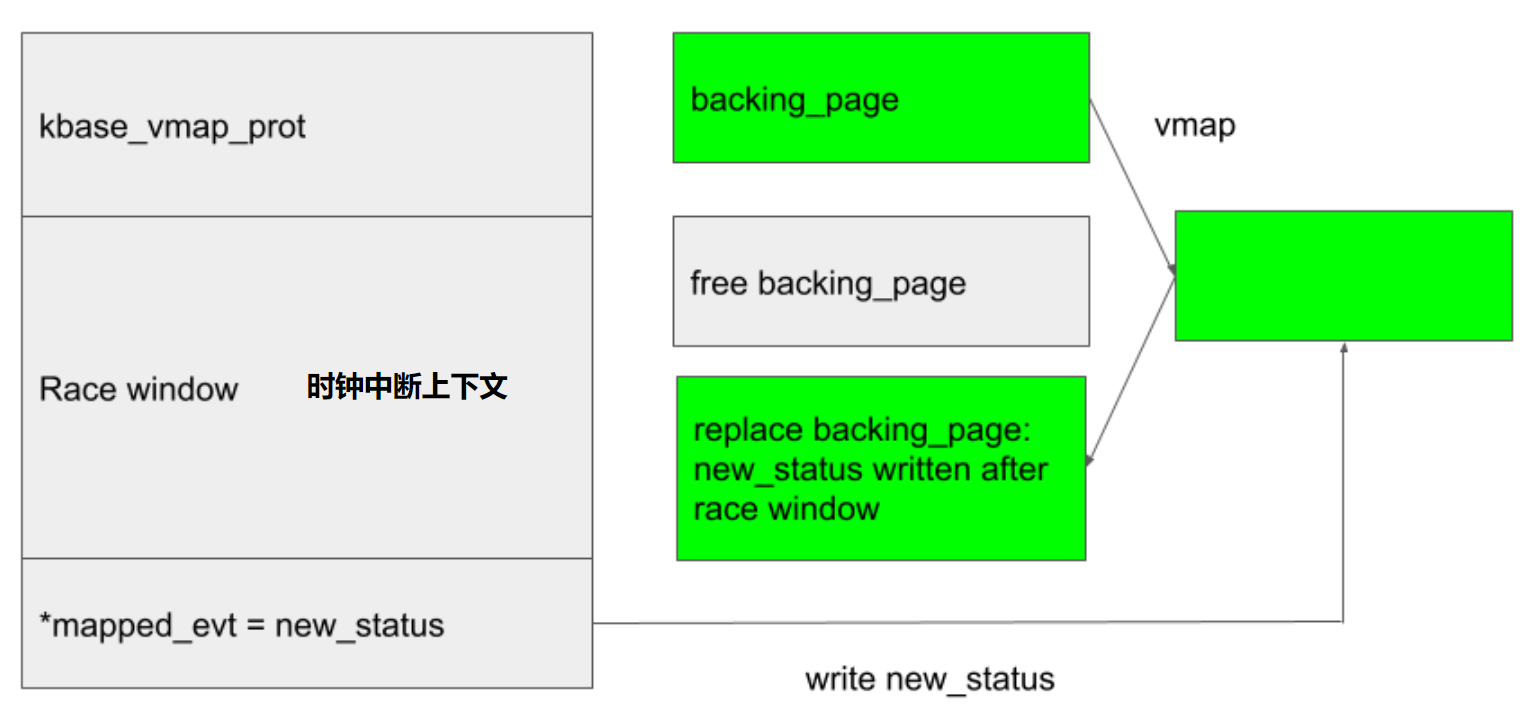
mapped_evt 在页内的偏移可控,写的内容为 0 或者 1,总结下来漏洞的原语是物理内存 UAF 写,写的值只能 0 或者 1
static inline struct kbase_mem_phy_alloc *kbase_alloc_create(
struct kbase_context *kctx, size_t nr_pages,
enum kbase_memory_type type, int group_id)
{
...
size_t alloc_size = sizeof(*alloc) + sizeof(*alloc->pages) * nr_pages;
...
if (alloc_size > KBASE_MEM_PHY_ALLOC_LARGE_THRESHOLD)
alloc = vzalloc(alloc_size);
else
alloc = kzalloc(alloc_size, GFP_KERNEL);
...
}
kbase_alloc_create 分配 kbase_mem_phy_alloc 时会调用 vzalloc 分配内存,vzalloc 的逻辑是根据大小计算分配的物理页数目,然后逐次调用 alloc_page 分配物理页,利用这个逻辑可以比较快速的占位刚刚释放的物理页(slab cross cache 时间相对较长)
根据之前的漏洞分析,我们知道 gpu_mappings 控制的物理页的释放,如果通过 UAF 将其修改为 0 或者 1,就能提前释放一个被别名映射的 kbase_mem_phy_alloc 中的物理页,导致物理页UAF
struct kbase_mem_phy_alloc {
struct kref kref;
atomic_t gpu_mappings;
size_t nents;
struct tagged_addr *pages;
struct list_head mappings;

实现无限制的物理页 UAF 读写后,就是常规的漏洞利用流程了。这个漏洞利用的核心是利用 GPU 驱动的物理内存管理结构,将一个受限的 UAF 写转化为 不受限的 物理页 UAF.
前面的案例都是利用 GPU 自身漏洞,这个案例则是将其他驱动、模块漏洞(摄像头驱动的 堆溢出漏洞) 的漏洞 转换为 GPU 漏洞,进而实现物理页 UAF 漏洞,核心思路与 CVE-2022-46395 一致,就是篡改 kbase_mem_phy_alloc 的 gpu_mappings 为 0,构造物理页 UAF
static inline struct kbase_mem_phy_alloc *kbase_alloc_create(
struct kbase_context *kctx, size_t nr_pages,
enum kbase_memory_type type, int group_id)
{
...
size_t alloc_size = sizeof(*alloc) + sizeof(*alloc->pages) * nr_pages;
...
alloc = kzalloc(alloc_size, GFP_KERNEL);
...
}
一个比较有意思的点是研究员发现及时安卓内核启用了 MTE,仍然有 50% 的概率能够完成溢出而不被检测,且及时 MTE 检测到溢出,也不会导致内核 Panic,只是杀掉用户进程,这样就给了攻击者无限尝试的能力,相当于 Bypass 了 MTE.

总结
从 CVE-2021-28663/CVE-2021-28664 开始研究人员逐渐重视并投入到 GPU 驱动安全领域,从一开始的挖掘 GPU 特有漏洞,到后面逐步将各种通用漏洞往 GPU 漏洞上转换,核心原因在于 GPU 驱动本身的能力太强大了,只要能够控制 GPU硬件的页表,就能实现任意物理页的读写,而且由于是独立的硬件,可以直接 Bypass 掉 CPU 侧的安全特性(比如 KNOX、PAC、MTE),Patch 内核代码。
GPU 安全研究还带来了另一个漏洞利用方向,GPU 驱动由于要管理物理内存,所以容易出现物理内存 UAF,物理 UAF 的利用手段被发掘后,大家发现这个原语实在太强大了,后面涌现了很多将不同漏洞转换为物理页UAF的技术,比如 Dirty Pagetable、USMA、 pipe_buffer->page 指针劫持等。
从 GPU 攻击的路径来看,也可以了解到一点,即漏洞的修复并不代表漏洞生命的结束,如果一个漏洞的原语过于强大、好用,就可以考虑将其他漏洞往这上面转换,从而复用历史的漏洞利用经验。
参考链接
转自博客园,作者hac425
该文章在 2024/12/16 9:37:05 编辑过






 400 186 1886
400 186 1886


