Linq(Language Integrated Query,集成查询语言),顾名思义就是用来查询数据的一种语言(可以看作是一组功能、框架特性的集合)。在.NETFramework3.5(大概2007年)引入C#,用统一的C#语言快速查询各种数据,如数据库、XML文档、对象集合等等。Linq的诞生对 C# 编程领域产生了深远而持久的影响,改变了开发人员对查询的思考方式。
- 使用简单:统一语法(链式方法语法、类似SQL的查询语法),智能提示。
- 类型安全:编译时强类型检查,减少运行时错误。
- 延迟执行,查询本身只是构建了一个表达式,在真正使用的时候(foreach、ToList、查询数据库)才会执行。
- 支持多种数据源:内存中的集合,以及各种外部数据库。
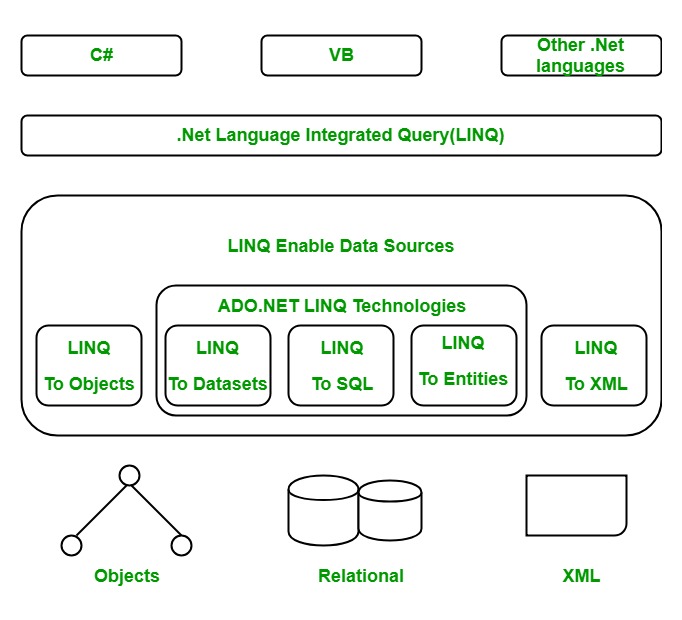
Linq支持查询任何实现了IEnumerable<T>接口的集合类型,基本上所有集合数据都支持Linq查询。如下示例:大于 5 的偶数,并倒叙排列取前三名
|
| var query = arr.Where(n => n > 5 && n % 2 == 0).OrderByDescending(n => n).Take(3); |
Linq 有两种语法风格,如下实例代码,一种是常规C#方法调用方式,另外一种是类似SQL的查询表达式。这两种语法其本质是一样的,编译后的中间语言(IL)是一样的,确实仅仅只是语法形式不同而已。
🔸链式方法:就是字面意思,函数式方法调用。这些方法都来自 IEnumerable 接口或 IQueryable 接口的扩展方法,这些方法提供了过滤、聚合、排序等多种查询功能。
🔸查询表达式:查询表达式由一组用类似于 SQL 的声明性语法所编写的子句组成。 每个子句依次包含一个或多个 C# 表达式,而这些表达式可能本身就是查询表达式,或者包含查询表达式。查询表达式必须以 from 子句开头,且必须以 select 或 group 子句结尾。
|
| var query = arr.Where(n => n > 5 && n % 2 == 0).OrderByDescending(n => n).Take(3); |
|
| var query2 = (from n in arr |
| where n > 5 && n % 2 == 0 |
| orderby n descending |
| select n).Take(3); |
| 比较 | 链式方法 | 查询表达式(SQL) |
|---|
| 特点 | 链式方法调用,函数式编程 | 类似SQL语句,自然语言,容易掌握 |
| 语法形式 | 点点点链式方法调用,Where().Select().Order() | 以from开头:from...where...select |
| 常用方法/语法 | System.Linq 上提供的扩展方法或第三方扩展:Where、OrderBy、Select、Skip、Take、Union | 仅支持编译器识别的关键字:from、where、orderby、group、join、let、select、into、in、on等 |
| 本质 | System.Linq 提供的扩展方法调用 | 编译为标准查询运算符方法调用,编译结果和链式方法一样 |
| 功能完整性 | 完整的Linq功能 | 有些能力没有对应语法(如Max),需要结合链式方法使用 |
📢 两种编写方式编译后生成的IL代码实际上是一样的,也可以混合使用,因此他们并没有性能差异。
查询表达式并不能实现获取前3个元素,此时就需要两者混合使用,
| var query = from u in list |
| where u.Age>14 |
| group u by u.Address into gu |
| orderby gu.Count() descending |
| select (gu.Key,gu.Count()); |
| query = query.Take(3); |
LINQ 提供了两种用途的架构:针对本地(内存)对象的本地查询,以及针对远程数据源(数据库)的解释性查询。两者的语法形式基本一样,都支持链式方法、查询表达式。
🔸本地查询:实现了针对IEnumerable的内存集合(数组、List)的查询,其Linq的扩展方法都在 System.Linq.Enumerable 类中。查询只是构建了一个可枚举的迭代装饰器序列,延迟在使用(消费)数据时执行。
🔸解释查询:解释查询是描述性的,实现了针对IQueryable(Table、DbSet)的远程数据查询,对应扩展方法都在 System.Linq.Queryable 类中。他们在运行时生成表达式树,并进行解释为SQL语句,在数据库中执行该SQL语句并获取数据。
| 比较 | 本地查询 Enumerable | 解释查询 Queryable |
|---|
| 操作对象 | 内存中的集合(IEnumerable<T>) | 外部数据源的查询接口(IQueryable<T>) |
| 延迟执行 | 支持,真正使用(消费)数据时才执行,如 foreach、ToList | 支持,消费数据时才翻译成SQL并在数据库中执行获取数据 |
| 执行原理 | 参数为委托方法,C#内部执行委托、迭代器 | 参数为表达式树,LINQ Provider 在运行时遍历该树转换为目标语言(如 SQL) |
| 谁来执行 | CLR本地执行,数据在内存中 | 数据库执行SQL,数据在数据库中 |
| 执行过程 | 本地逐个元素迭代调用委托 | 数据库中执行SQL,返回查询结果 |
| 使用场景 | List、Array、普通内存数据 | Entity Framework、LINQ to SQL、MongoDB 查询 |
| 语法 | 都支持链式方法、表达式查询 | 同样支持链式方法、表达式查询 |
| Linq方法在哪里? | System.Linq.Enumerable 静态类 | System.Linq.Queryable 类,方法和 Enumerable 大部分对应。有些方法并不能生成数据库兼容的SQL语法。 |
| 扩展性 | 内存查询支持任意C#方法,扩展性强 | 受限,只能使用数据库兼容的方法。如正则表达式SQLServer就不支持。 |
| 结合使用 | 本地数据只能用本地查询 | 远程数据可以结合本地查询混用。 |
IQueryable 继承自 IEnumerable,因此解释查询可以转换为本地查询,query.AsEnumerable(),不过需谨慎使用,会将数据库的相应数据都加载到内存中。
| public interface IQueryable<out T> : IEnumerable<T>, IEnumerable, IQueryable |
| { |
| } |
📢表达式树是一个微型的代码DOM结构,树中的节点是Expression类型的节点,涵盖各种语法形式,如参数、变量、常量、赋值、比较、循环等等。表达式树可以转换(Compile)为委托,反之则不能。
延迟执行是指查询代码不会立刻执行,而是在正真取数的时候才会执行。他是Linq最主要的特点,是优点,也不全是,有些需要注意的地方。
- 并不是所有的Linq方法都是延迟的,如:First()、Last()、ToArray()、ToList(),及Count、Max等聚合计算方法会立即执行。
- 如果数据源变了,结果也会变化。
| List<int> list = [2,3,9,4,5]; |
| var query = list.Where(s=>s>5); |
| Console.WriteLine(query.Sum()); |
| list.Add(6); |
| Console.WriteLine(query.Sum()); |
- 重复取数时,查询也会重复执行,可能会浪费性能,特别是复杂、耗时的查询。避免的方式就是
query.ToList() 一次性立即获取数据。 - Lambda变量捕获,变量的值在真正执行查询的时候才会获取,这是方法闭包的特点。
| List<int> list = [2,3,9,4,5]; |
| int n = 5; |
| var query = list.Where(s=>s>n); |
| n = 4; |
| Console.WriteLine(query.Sum()); |
为了支持延迟执行,Linq内部封装了很多迭代装饰器,偷偷看了下源码,如 WhereIterator、SelectEnumerableIterator、ReverseIterator、UnionIterator 等,都是Linq内部的迭代装饰器。迭代装饰器会保留输入序列的引用及其他相关参数,仅当枚举结果时才会执行。
迭代序列装饰器本身继承自IEnumerable,因此就支持装饰器之间的嵌套。下面为迭代装饰器序列基类的源码 Iterator.cs。
| internal abstract class Iterator<TSource> : IEnumerable<TSource>, IEnumerator<TSource> |
| { |
| private readonly int _threadId; |
| internal int _state; |
| internal TSource _current = default!; |
| } |
内存集合的Linq扩展方法,基本都来自Enumerable类,参考官方 Enumerable 类。用于数据库的解释性查询方法在 System.Linq.Queryable 类中,方法和 Enumerable 基本上都是对应的。基本上所有的Linq方法都在这里汇总:
| 方法 | 说明 |
|---|
| Chunk(Int32) | 分块拆分为多个固定大小的数组,返回IEnumerable<TSource[]>,内部每次迭代会构建一个数组new TSource[arraySize] |
| Append(T) | 末尾追加一个元素,原理是内部构建了一个新的迭代器AppendPrepend1Iterator实现返回这个元素。 |
| Prepend(T) | 在前面追加一个元素,原理同上,是同一个AppendPrepend1Iterator |
| 🔸聚合计算,立即执行 |
|
| Count() | 获取集合中元素的数量,可指定条件参数Func。arr.Count(),内部原理比较简单,如果集合是ICollection等,则直接获取Count,否则只能e.MoveNext()一个一个的数了。 |
| TryGetNonEnumeratedCount | 获取元素数量,在不真正遍历(不枚举)集合的情况下,尽量尝试快速拿到集合元素的数量 |
| Max() | 返回最大的那个元素。截止.NET8,整数类型用了Vector提升性,其他循环比较,性能一般😒。 |
| Min() | 返回最小的那个元素,性能原理同Max |
| Average() | 计算平均值,对于数值类型,内部用到了Vector⭐,性能还是不错的。var a = arr.Average() |
| Sum() | 求和,arr1.Sum() |
| Aggregate(Func) | 执行累加器函数,函数的的输出为作为下一轮迭代的输入,依次迭代执行。
示例,计算序列最大值:var max = arr.Aggregate((acc,n)=>acc>n?acc:n) |
| 🔸条件判断 |
|
| Contains(T) | 判断是否包含指定元素,返回bool,可指定比较器。bool f = arr.Contains(6) |
| Any() | 集合是否包含元素,判断集合是否不为空。if(arr.Any()){} |
| Any(Func) | 集合是否包含指定条件的元素,示例:是否有人考试满分,bool flag = arr.All(n=>n==100) |
| All(Func) | 所有元素是否满足条件,示例:是否所有同学都及格了,bool flag = arr.All(n=>n>=60) |
| SequenceEqual(IEnumerable) | 序列相等比较,比较两个序列是否相同,长度相同、每个元素相等则返回True |
| 🔸元素选择 |
|
| First() | 返回第一个元素,如果一个都没有抛出异常,arr1.First() |
| FirstOrDefault() | 返回第一元素,如果一个都没有则返回默认值,arr1.FirstOrDefault() |
| Last() | 返回最后一个元素,如果一个都没有抛出异常。如果不是常规集合,会foreach循环所有😒。 |
| LastOrDefault() | 同上,如果一个都木有则返回默认值 |
| Single()、SingleOrDefault() | 获取唯一元素,如果元素数量大于1则抛出异常。这个方法在数据库按主键查询时比较有用。 |
| ElementAt(Index) | 返回指定索引Index位置的元素,arr.ElementAt(0)。还有个更安全的 ElementAtOrDefault |
| DefaultIfEmpty(defaultT) | 如果集合为空(集合中没有元素)返回含一个默认值的IEnumerable,否则返回原序列。 |
| 🔸筛选查询 |
|
| Where(Func) | 条件查询,最常用的Linq函数了,arr1.Where(s=>s>5) |
| Select(selector) | 返回指定Key(元素选择处理器结果)的集合,list.Select(s=>s.Name+s.Age) |
| SelectMany() | 将每个元素的“内部集合”展开合并为一个大集合,list.SelectMany(s=>s.Name.Split('-')) |
| Distinct() | 去重,arr.Distinct(),内部使用HashSet<TSource>来去重。DistinctBy>可指定键Key。 |
| OfType() | 根据类型T筛选集合,源码中用obj is TResult来筛选,不符合的丢弃。list.OfType<double>() |
| Skip(int count) | 跳过指定数量的元素,返回剩余的元素,arr1.Skip(5) |
| SkipLast(int count) | 忽略后面的元素,返回前面剩余的元素。arr1.SkipLast(3) |
| SkipWhile(Func) | 从开头跳过符合条件的元素,直到遇到不符合条件时停下,返回剩下的元素。 |
| Take(int count) | 返回前n个元素,Skip的逆运算,Take(3) |
| TakeLast(int count) | 返回最后n个元素,arr1.TakeLast(3) |
| TakeWhile(Func) | 从开头返回符合条件的元素,直到遇到不符合条件时停下,与SkipWhile相反arr1.TakeWhile(s=>s<5) |
| 🔸排序分组 |
|
| Order() | 升序排列集合,arr2.Order() |
| OrderBy(TKey) | 指定Key键升序排列集合,list.OrderBy(s=>s.Age) |
| OrderByDescending(TKey) | 指定Key键降序排列集合,list.OrderByDescending(s=>s.Age) |
| ThenBy、ThenByDescending | 二次排序,跟着OrderBy使用,设置第二排序键。list.OrderBy(s=>s.Grade).ThenBy(s=>s.Age) |
| Reverse() | 反转序列中元素的顺序,arr2.Reverse()。内部源码是创建了一个数组来实现翻转,性能不佳😒,数组推荐使用Array.Reverse(),原地翻转,不会创建额外对象。 |
| GroupBy | 按指定的Key分组,返回一个分组集合IGrouping<TKey, TSource>,list.GroupBy(s=>s.Name) |
| GroupJoin | 带分组的连接(Join)操作,类似Sql中的Left Join + 分组,每个「左边元素」对应到「右边的一组元素」 |
| 🔸多集合操作 |
|
| Union(IEnumerable) | 并集,合并两个集合并去重,arr1.Union(arr2) |
| Intersect(IEnumerable) | 交集(Intersect /ˌɪntəˈsekt/ 相交),返回两个集合都包含的元素。IntersectBy 可指定键Key。 |
| Except(IEnumerable) | 移除(Except /ɪkˈsept/ 除外)arr1.Except(arr2)移除arr2中也存在的元素。ExceptBy可指定键Key。 |
| Concat(IEnumerable) | “合并”两个序列集合(),内部由私有的ConcatIterator实现的连接迭代,arr.Concat([3]) |
| Join(arr2, k2,k1,Func) | 两个“表”内连接,类似Sql中的 Inner Join,用于两个不同类型元素的的连接,两个表Key匹配的元素合并 |
| Zip | 就像拉链(zipper)一样,把两个序列一对一地配对合并成一个新序列,arr1.Zip(arr2,(n1,n2)=>n1+n2) |
| 🔸转换,ToXX立即执行 | ❗谨慎使用,会创建新的集合对象 |
| Cast() | 强制类型转换,内部使用强制转换“(TResult)obj” |
| ToArray() | 从 IEnumerable 创建新数组,慎用。var narr = arr1.Order().ToArray() |
| ToList() | 从 IEnumerable 创建新List,arr1.Take(3).ToList() |
| ToHashSet | 从 IEnumerable 创建新HashSet(不可重复集合,自动去重),arr1.ToHashSet() |
| ToDictionary() | 从 IEnumerable 创建新字典Dictionary<TK,TV>,list.ToDictionary(s=>s.Name,s=>s.Age) |
| ToLookup() | 从 IEnumerable 创建新 Lookup(分组的字典),arr1.ToLookup(s=>s%2) |
| 🔸其他 |
|
| Range(start, end) | 静态方法,创建一个连续的序列,可用来创建测试数据,Enumerable.Range(1,10).ToArray() |
| Repeat(T, count) | 静态方法,创建一个重复值的序列,Enumerable.Repeat(18,10) |
| Empty() | 静态方法,获得一个空的序列,Enumerable.Empty<int>().Any(); //false |
| AsEnumerable() | 返回自己,什么也不干。在Linq to SQL中可以强制让后续操作在本地内存中进行,而不会翻译成SQL。 |
|
|
根据用户输入条件,构建动态查询条件,使用 Skip 和 Take 实现分页。
| var query = list.AsEnumerable(); |
| if (!string.IsNullOrWhiteSpace(name)) |
| query = query.Where(s => s.Name.Contains(name, StringComparison.OrdinalIgnoreCase)); |
| if (age.HasValue) |
| query = query.Where(s => s.Age == age); |
| if (!string.IsNullOrWhiteSpace(address)) |
| query = query.Where(s => s.Address.Contains(address)); |
|
| query = query |
| .Skip((pageNumber - 1) * pageSize) |
| .Take(pageSize); |
|
| var result = query.ToArray(); |
本地查询扩展是很容易的,基于IEnumerable<T>实现扩展方法即可。IQueryable扩展则要考虑数据库的支持和映射,一般无需自定义扩展。
|
| public static IEnumerable<T> AlternateElements<T>(this IEnumerable<T> source) |
| { |
| int index = 0; |
| foreach (T element in source) |
| { |
| if (index % 2 == 0) |
| { |
| yield return element; |
| } |
|
| index++; |
| } |
| } |
|
|
| var query = list.AlternateElements(); |
©️版权申明:版权所有@安木夕,本文内容仅供学习,欢迎指正、交流,转载请注明出处!原文编辑地址-语雀
该文章在 2025/7/2 9:59:31 编辑过






 400 186 1886
400 186 1886


