SQL 表达式(Expression)是 SQL 中用于计算值的基本单元,例如:
- 条件判断:
CASE WHEN status='active' THEN 1 ELSE 0 END - 日期操作:
created_at + INTERVAL '7 days'
优化 SQL 表达式的基本目标是:减少计算开销、避免索引失效、提升执行效率、增强可读性,并让数据库优化器能生成更高效的执行计划。
下面我们从 SQL 表达式本身的逻辑、性能、索引兼容性等方面进行表达式粒度的精细化调优,彻底重构 SQL 逻辑,不仅提升性能,更增强代码的可维护性与健壮性;同时,我们对 SQL 表达式的未来调优方向作一些探讨,仅供参考。
一、简化表达式逻辑,减少冗余计算
复杂表达式不仅影响可读性,还会增加 CPU 开销,特别是在高频执行或数据量大的场景下。因此,我们首先要消除重复计算和降低嵌套复杂度等等。
1、消除重复计算,避免多次执行相同逻辑
当同一个表达式在 SELECT、WHERE、ORDER BY 等 SQL 子句中多次出现时,数据库可能重复计算,造成资源浪费。
❌ (1)优化前(重复计算 amount * 1.1):
SELECT
order_id,
amount * 1.1 AS total -- 计算一次
FROM orders
WHERE amount * 1.1 > 1000 -- 再次计算
ORDER BY amount * 1.1; -- 第三次计算
问题:同一表达式被计算三次,每行数据都要重复运算,CPU 开销变大。
✅ (2)优化后(使用 CTE 暂存结果):
WITH temp AS (
SELECT
order_id,
amount * 1.1 AS total -- 只计算一次
FROM orders
)
SELECT order_id, total
FROM temp
WHERE total > 1000
ORDER BY total;
优势:我们通过公用表表达式(CTE)将表达式结果缓存,后续子句直接引用,避免重复计算,提升执行效率。
2、避免不必要的函数嵌套,降低解析成本
多层函数嵌套(如:SUBSTRING(LOWER(email), ...))会显著增加解析和执行时间,特别在大表查询中影响明显。
❌ (1)优化前(深层嵌套):
SELECT *
FROM users
WHERE SUBSTRING(LOWER(email), POSITION('@' IN email) + 1) = 'example.com';
问题:LOWER(email) 和 POSITION(...) 在每行中都被嵌套调用,且 POSITION 依赖原始列,无法提前缓存。
✅ (2)优化后(拆分表达式,提升可读性与性能):
SELECT *
FROM (
SELECT *,
LOWER(email) AS lower_email,
POSITION('@' IN email) AS at_pos
FROM users
) AS sub
WHERE SUBSTRING(lower_email, at_pos + 1) = 'example.com';
优势:
- 若后续需多次使用
lower_email,可避免重复调用 LOWER()。
二、优化条件表达式,提升过滤效率与索引利用率
条件表达式是 SQL 性能的重要瓶颈之一。不当写法会导致全表扫描、索引失效或低效短路判断。
1、避免在索引列上使用函数或运算(防止索引失效)
我们对索引列直接应用函数(如:YEAR(created_at))或表达式运算(如:price * 0.9),会使数据库无法使用 B+ 树索引,被迫进行全表扫描。
❌ (1)优化前(索引失效):
-- created_at 有索引,但 YEAR() 函数导致无法使用
SELECT * FROM orders WHERE YEAR(created_at) = 2023;
问题:YEAR(created_at) 是一个表达式,数据库无法将其与索引中的原始值直接匹配。
✅ (2)优化后(改写为范围比较,支持索引):
SELECT * FROM orders
WHERE created_at >= '2023-01-01'
AND created_at < '2024-01-01';
原理:我们将“函数作用于列” → 改为“列与常量比较”,使优化器能利用索引快速定位数据范围。
2、简化 WHERE 子句的逻辑判断,提升短路效率
复杂布尔表达式,若顺序不当,可能导致低效执行。
✅ (1)推荐写法:
**用 IN 替代多个 OR**:
a = 1 OR a = 2 OR a = 3 → a IN (1,2,3),数据库对 IN 的优化成熟一些。
避免 NOT 操作符:
NOT a = 1 → a <> 1,部分数据库对 NOT 的索引利用较差。
用 EXISTS 替代 IN 处理大表关联:
EXISTS 在找到第一条匹配记录后,即停止扫描,适合大表过滤。
(2)示例:EXISTS 替代 IN 提升效率
-- ❌ 子查询结果大时低效
SELECT * FROM orders
WHERE user_id IN (SELECT id FROM users WHERE status = 1);
-- ✅ 找到匹配即停止,效率更高
SELECT * FROM orders o
WHERE EXISTS (
SELECT 1 FROM users u
WHERE u.id = o.user_id AND u.status = 1
);
3、优化 LIKE 表达式,以支持索引匹配
LIKE 模式,以通配符开头(如:%abc),无法使用索引。
❌ (1)低效表达式(前导通配符):
SELECT * FROM products WHERE name LIKE '%phone%'; -- 全表扫描
✅ (2)优化表达式(后缀匹配):
SELECT * FROM products WHERE name LIKE 'iphone%'; -- 可走索引
✅ (3)进阶:使用表达式索引支持模糊查询
-- PostgreSQL:创建 trigram 索引
CREATE INDEX idx_products_name_trgm ON products USING gin (name gin_trgm_ops);
SELECT * FROM products WHERE name ILIKE '%phone%'; -- 可走索引
三、优化聚合与分组表达式
聚合表达式(如:SUM(price * qty)),若未合理过滤,会导致不必要的全表扫描和内存消耗。
1、限制聚合范围,减少数据量
我们应在聚合前,尽可能通过 WHERE 过滤无关数据,避免对无效行进行计算。
❌ (1)优化前(全表聚合后过滤):
SELECT user_id, SUM(amount)
FROM orders
GROUP BY user_id
HAVING SUM(amount) > 10000; -- 聚合后过滤,计算量大
✅ (2)优化后(先过滤再聚合):
SELECT user_id, SUM(amount)
FROM orders
WHERE amount > 0 -- 排除无效数据,减少聚合行数
GROUP BY user_id
HAVING SUM(amount) > 10000;
优势:减少参与聚合的数据量,显著降低 CPU 和内存开销。
2、避免 SELECT * 与不必要的分组列
分组查询中,SELECT 应仅包含聚合列和分组列,避免引入无关字段。
❌ (1)低效表达式(冗余列):
SELECT * FROM orders GROUP BY user_id; -- 包含非分组列,语法错误或低效
✅ (2)优化后(精简列):
SELECT user_id, COUNT(*) AS order_count, SUM(amount) AS total_amount
FROM orders
GROUP BY user_id;
优势:减少数据传输量,避免歧义,提升执行效率。
四、利用数据库特性与索引优化表达式
现代数据库,支持多种高级索引机制,合理利用可大幅提升表达式性能。
1、创建表达式索引(Functional Index),固化高频计算
若某表达式需频繁使用(如:LOWER(name)、price * quantity),可为其创建索引,将计算结果“物化”。
(1)示例:按姓氏首字母排序
-- 频繁查询
SELECT * FROM users ORDER BY SUBSTRING(last_name, 1, 1);
✅ (2)创建表达式索引(PostgreSQL):
CREATE INDEX idx_users_last_name_initial
ON users (SUBSTRING(last_name, 1, 1));
-- ORDER BY 可直接使用索引
✅ (3)MySQL:使用虚拟列 + 索引
ALTER TABLE users
ADD COLUMN last_name_initial VARCHAR(1)
AS (SUBSTRING(last_name, 1, 1)) STORED;
CREATE INDEX idx_last_name_initial ON users(last_name_initial);
适用场景:DATE(created_at)、COALESCE(nickname, username)、amount * 1.1 等等。
2、避免隐式类型转换,确保表达式类型一致
表达式中,若存在类型不匹配(如:id = '123'),数据库会进行隐式转换,导致索引失效。
❌ (1)低效表达式(隐式转换):
SELECT * FROM orders WHERE order_no = '12345'; -- order_no 为 INT
问题:数据库需将每行 order_no 转为字符串比较,无法使用索引。
✅ (2)优化表达式(显式类型一致):
SELECT * FROM orders WHERE order_no = 12345; -- 类型一致,可走索引
通用规则:确保表达式两边数据类型一致,避免 col_string = 123 或 col_int = '123'。
3、优化 CASE WHEN 与 COALESCE 表达式
CASE WHEN 分支过多或顺序不合理,会增加判断开销。
❌ (1)低效表达式(高频值靠后):
CASE
WHEN status = 'inactive' THEN 'red'
WHEN status = 'pending' THEN 'yellow'
WHEN status = 'active' THEN 'green' -- 最常见,但判断靠后
END
✅ (2)优化表达式(高频值前置):
CASE
WHEN status = 'active' THEN 'green' -- 最常见,优先判断
WHEN status = 'inactive' THEN 'red'
WHEN status = 'pending' THEN 'yellow'
END
✅ (3)用 COALESCE 替代空值判断:
-- ❌ 冗长
CASE WHEN nickname IS NULL THEN username ELSE nickname END
-- ✅ 简洁高效
COALESCE(nickname, username)
五、常量折叠与短路求值:提升表达式执行效率
1、常量折叠(Constant Folding)
在编写 SQL 时,我们应提前计算常量表达式,避免数据库重复解析。
❌ (1)低效表达式:
amount * (1 + 0.1 + 0.05) -- 每行都计算 1+0.1+0.05
✅ (2)优化表达式:
amount * 1.15 -- 提前计算常量
2、利用短路求值优化布尔表达式
将“低成本”或“高命中率”条件前置,提升 OR/AND 短路效率。
-- 优先判断简单条件,避免调用昂贵函数
WHERE user_id IN (1001, 1002) OR slow_function(data) = 'valid'
六、利用布尔短路机制优化条件表达式执行顺序
SQL 中的 AND 和 OR 支持短路求值(short-circuit evaluation)。当左侧条件已能决定整体结果时,右侧表达式不会被执行。合理安排条件顺序可避免执行昂贵函数。
❌ 1、低效表达式(高成本函数前置):
SELECT *
FROM logs
WHERE slow_regex_match(message, 'error.*timeout') -- 耗时函数
AND level = 'ERROR'; -- 简单条件
问题:即使 level 不是 'ERROR',仍会先执行耗时的正则匹配,造成大量无效计算。
✅ 2、优化表达式(低成本条件前置,利用短路):
SELECT *
FROM logs
WHERE level = 'ERROR' -- 快速过滤,失败则跳过右侧
AND slow_regex_match(message, 'error.*timeout'); -- 只对 ERROR 级别执行
优势:
- 利用
AND 的短路特性:若 level ≠ 'ERROR',则不执行 slow_regex_match; - 显著减少函数调用次数,特别在
level 分布不均时效果显著。
⚠️ 注意:不同数据库对短路的保证程度不同(如:PostgreSQL 保证,Oracle 不完全保证),但多数现代数据库会基于成本模型自动重排,人为优化仍具价值。
七、避免在表达式中使用标量子查询(Scalar Subquery)
在 SELECT 或 WHERE 中,嵌入标量子查询(返回单值的子查询),会导致每行都执行一次子查询,形成“N+1 查询”问题。
❌ 1、低效表达式(标量子查询嵌入表达式):
SELECT
order_id,
amount,
-- 每行都执行一次子查询,性能极差
(SELECT AVG(amount) FROM orders o2 WHERE o2.user_id = o1.user_id) AS user_avg_amount,
amount - (SELECT AVG(amount) FROM orders o2 WHERE o2.user_id = o1.user_id) AS diff_from_avg
FROM orders o1
WHERE user_id IN (101, 102, 103);
问题:AVG(amount) 子查询在每行中重复执行,即使 user_id 相同也重复计算。
✅ 2、优化表达式(使用窗口函数或 JOIN 预计算):
-- 方法一:使用窗口函数(推荐)
SELECT
order_id,
amount,
AVG(amount) OVER (PARTITION BY user_id) AS user_avg_amount, -- 一次扫描完成
amount - AVG(amount) OVER (PARTITION BY user_id) AS diff_from_avg -- 避免重复子查询
FROM orders
WHERE user_id IN (101, 102, 103);
-- 方法二:使用 JOIN 预计算平均值
WITH user_avg AS (
SELECT user_id, AVG(amount) AS avg_amount
FROM orders
GROUP BY user_id
)
SELECT
o.order_id,
o.amount,
ua.avg_amount AS user_avg_amount,
o.amount - ua.avg_amount AS diff_from_avg
FROM orders o
JOIN user_avg ua ON o.user_id = ua.user_id
WHERE o.user_id IN (101, 102, 103);
优势:
- 窗口函数:在一次扫描中完成所有计算,避免重复执行;
- JOIN + CTE:将昂贵计算提前物化,提升可读性与性能。
八、避免 NULL 值参与算术表达式导致结果为 NULL
SQL 中任何与 NULL 的算术运算结果均为 NULL,可能导致意外的空值传播。
❌ 1、低效表达式(未处理 NULL):
SELECT
product_id,
price * quantity AS total_revenue -- 若 quantity 为 NULL,total_revenue 也为 NULL
FROM sales;
问题:即使 price 有效,只要 quantity 为 NULL,结果就为 NULL,影响后续统计。
✅ 2、优化表达式(使用 COALESCE 或 CASE 处理 NULL):
SELECT
product_id,
price * COALESCE(quantity, 0) AS total_revenue -- 将 NULL 视为 0
FROM sales;
优势:
- 更符合业务语义(如:“未记录数量”视为“0 销售”)。
建议:对可能为 NULL 的数值字段,在表达式中显式使用 COALESCE(col, 0) 或 NULLIF(col, 0) 进行处理。
九、使用位运算替代多状态字段的逻辑判断
当状态字段采用位掩码(bitmask)设计时(如:status = 5 表示 1 | 4,即“启用 + 验证”),使用位运算比字符串匹配或 IN 列表更高效。
❌ 1、低效表达式(使用字符串或 IN 列表模拟状态):
-- 假设状态用字符串存储,如:'active,verified'
SELECT *
FROM users
WHERE status LIKE '%active%' AND status LIKE '%verified%';
-- 无法使用索引,且模糊匹配效率低
✅ 2、优化表达式(使用位掩码 + 位运算):
-- 假设状态为整数位掩码:
-- active = 1 (0b0001), verified = 2 (0b0010), premium = 4 (0b0100)
SELECT *
FROM users
WHERE (status & 1) = 1 -- 检查是否 active
AND (status & 2) = 2; -- 检查是否 verified
优势:
适用场景:权限系统、用户状态、订单标志位等。
十、使用正则表达式或 SIMILAR TO 替代复杂 LIKE 模式
当需要匹配复杂文本模式时,多个 LIKE 或 OR 组合效率低下,且难以维护。
❌ 1、低效表达式(多个 LIKE OR 组合):
SELECT *
FROM logs
WHERE message LIKE '%error%'
OR message LIKE '%fail%'
OR message LIKE '%timeout%'
OR message LIKE '%exception%';
-- 多次字符串扫描,性能差
✅ 2、优化表达式(使用正则表达式,PostgreSQL/MySQL 8.0+):
-- PostgreSQL / MySQL 8.0+
SELECT *
FROM logs
WHERE message ~* 'error|fail|timeout|exception'; -- ~* 表示不区分大小写的正则匹配
✅ 3、或使用 SIMILAR TO(部分数据库支持):
SELECT *
FROM logs
WHERE message SIMILAR TO '%(error|fail|timeout|exception)%';
优势:
- 正则表达式更灵活,支持复杂模式(如:数字、特定格式);
⚠️ 注意:正则表达式仍可能全表扫描,建议配合全文索引或分区使用。
十一、避免在表达式中使用 DISTINCT 或 GROUP BY 冗余字段
在聚合表达式中,不必要的 DISTINCT 或 GROUP BY 字段会增加排序和去重开销。
❌ 1、低效表达式(冗余 DISTINCT):
SELECT
user_id,
COUNT(DISTINCT user_id) AS user_count -- 无意义:每个 user_id 本身唯一
FROM orders
GROUP BY user_id;
问题:COUNT(DISTINCT user_id) 在 GROUP BY user_id 下恒为 1,完全冗余。
✅ 2、优化表达式(移除冗余):
SELECT
user_id,
1 AS user_count -- 直接赋值,无需计算
FROM orders;
3、更典型示例:避免 DISTINCT 在非必要场景
-- ❌ 错误理解:认为 COUNT(*) 需去重
SELECT COUNT(DISTINCT *) FROM users; -- 语法错误!
-- ❌ 低效:对主键去重
SELECT COUNT(DISTINCT id) FROM users; -- id 是主键,无需 DISTINCT
-- ✅ 正确
SELECT COUNT(*) FROM users;
建议:仅在真正需要去重的字段上使用 DISTINCT,如:COUNT(DISTINCT email)。
十二、使用 NULLIF 避免除零错误或无效计算
在算术表达式中,除以零会导致错误或异常。使用 NULLIF 可安全规避。
❌ 1、低效表达式(可能除零):
SELECT
revenue / cost AS profit_ratio -- 若 cost = 0,报错或返回无穷
FROM financials;
✅ 2、优化表达式(使用 NULLIF 安全除法):
SELECT
revenue / NULLIF(cost, 0) AS profit_ratio -- 若 cost=0,返回 NULL 而非报错
FROM financials;
优势:
- 返回
NULL 更符合业务语义(成本为 0 时利润比无意义); - 比
CASE WHEN cost = 0 THEN NULL ELSE revenue/cost END 更简洁。
十三、避免在 WHERE 或 JOIN 中频繁解析 JSON 字段
现代数据库(如:PostgreSQL、MySQL、SQL Server)支持 JSON 类型,但频繁调用 ->、->>、JSON_VALUE 等函数会导致每行都解析 JSON,性能极差。
❌ 1、低效表达式(每次查询都解析 JSON):
-- users 表:id, profile JSON(如:{"age": 25, "city": "Beijing"})
SELECT *
FROM users
WHERE (profile->>'age')::INT > 30
AND profile->>'city' = 'Shanghai';
问题:
✅ 2、优化表达式(创建表达式索引 + 使用索引友好写法):
-- PostgreSQL:创建表达式索引
CREATE INDEX idx_users_age ON users (((profile->>'age')::INT));
CREATE INDEX idx_users_city ON users ((profile->>'city'));
-- 查询可走索引
SELECT *
FROM users
WHERE (profile->>'age')::INT > 30
AND profile->>'city' = 'Shanghai';
✅ 3、更优方案:使用生成列(Generated Column)+ 普通索引
-- MySQL 5.7+/PostgreSQL 12+
ALTER TABLE users
ADD COLUMN age INT AS ((profile->>'age')::INT) STORED,
ADD COLUMN city TEXT AS (profile->>'city') STORED;
CREATE INDEX idx_users_age ON users(age);
CREATE INDEX idx_users_city ON users(city);
-- 查询直接使用生成列
SELECT * FROM users WHERE age > 30 AND city = 'Shanghai';
优势:
十四、使用布尔表达式替代 CASE WHEN 实现更高效逻辑判断
CASE WHEN 虽然灵活,但解析和执行成本高于原生布尔表达式。当逻辑可转化为布尔运算时,我们应优先使用。
❌ 1、低效表达式(用 CASE WHEN 判断布尔结果):
SELECT
order_id,
CASE
WHEN status = 'shipped' AND payment_status = 'paid'
THEN 1
ELSE 0
END AS is_deliverable
FROM orders;
问题:CASE WHEN 需要解析分支逻辑,而此场景本质是布尔判断。
✅ 2、优化表达式(直接使用布尔表达式转整数):
-- PostgreSQL/MySQL:布尔值可隐式转为 0/1
SELECT
order_id,
(status = 'shipped' AND payment_status = 'paid')::INT AS is_deliverable
FROM orders;
-- 或使用 CAST
SELECT
order_id,
CAST((status = 'shipped' AND payment_status = 'paid') AS INT) AS is_deliverable
FROM orders;
优势:
适用场景:标志位计算、状态组合判断、评分逻辑等。
十五、优化日期间隔计算:避免 INTERVAL 和 DATEADD 的隐式转换
日期表达式若写法不当,可能导致时区转换、精度丢失或索引失效。
❌ 1、低效表达式(使用字符串拼接或复杂函数):
-- 错误:字符串比较不准确
SELECT * FROM events
WHERE created_at > '2023-01-01 00:00:00'::TEXT || ' + 7 days'; -- 语法错误!
-- 低效:使用函数
SELECT * FROM events
WHERE created_at > NOW() - INTERVAL '30 days';
-- 若 created_at 有索引,某些数据库可能无法有效利用
✅ 2、优化表达式(使用参数化或预计算时间点):
-- 推荐:将计算移出 SQL,由应用传参
-- 假设应用计算 cutoff_time = NOW() - 30 days
SELECT * FROM events
WHERE created_at > '2023-12-01 00:00:00'; -- 常量,可走索引
-- 或使用绑定变量(PreparedStatement)
-- WHERE created_at > ?
✅ 3、使用表达式索引支持动态时间偏移
-- PostgreSQL:创建索引支持“最近30天”查询
CREATE INDEX idx_events_recent ON events (created_at)
WHERE created_at > NOW() - INTERVAL '30 days';
-- 查询可走索引
SELECT * FROM events
WHERE created_at > NOW() - INTERVAL '30 days';
优势:部分数据库(如:PostgreSQL)支持部分索引(Partial Index),可精准加速特定时间范围查询。
十六、使用生成列(Generated Column)固化复杂表达式
高频使用的复杂表达式(如:price * (1 + tax_rate)),若每次都计算,开销大,我们可通过生成列“物化”结果。
❌ 1、低效表达式(每次查询都计算):
SELECT
product_id,
price * (1 + tax_rate) AS final_price
FROM products;
✅ 2、优化表达式(使用存储型生成列):
-- MySQL
ALTER TABLE products
ADD COLUMN final_price DECIMAL(10,2)
AS (price * (1 + tax_rate)) STORED;
CREATE INDEX idx_products_final_price ON products(final_price);
-- 查询直接使用
SELECT product_id, final_price FROM products;
-- PostgreSQL
ALTER TABLE products
ADD COLUMN final_price DECIMAL
GENERATED ALWAYS AS (price * (1 + tax_rate)) STORED;
优势:
⚠️ 注意:STORED 占用磁盘空间,VIRTUAL 不存储但每次读取计算,需权衡。
十七、编写 SIMD(向量化执行)友好的表达式(适用于列式数据库)
在 ClickHouse、Doris、Snowflake 等列式数据库中,SQL 引擎支持 SIMD(单指令多数据)并行计算。简单、规则的表达式更易被向量化执行。
❌ 1、低效表达式(嵌套函数、条件复杂,难以向量化):
-- ClickHouse 示例
SELECT
CASE
WHEN x > 0 THEN sqrt(log(x + 1))
WHEN x = 0 THEN 0
ELSE -sqrt(log(-x + 1))
END AS f_x
FROM data;
问题:多层嵌套、条件分支复杂,编译器难以生成 SIMD 指令。
✅ 2、优化表达式(拆分为向量化友好的形式):
-- 使用向量化友好的函数组合
SELECT
sign(x) * sqrt(log(abs(x) + 1)) AS f_x
FROM data;
优势:
sign()、abs()、log()、sqrt() 均为向量化友好函数;- 整体表达式可被编译为 SIMD 指令,单条指令处理多个数据;
建议:在列式数据库中,优先使用:
- 向量化函数(
abs, round, pow, exp 等);
十八、避免在表达式中使用 RAND() 或 UUID() 导致不可预测结果
RAND()、NEWID()、GEN_RANDOM_UUID() 等随机函数在表达式中可能每行调用多次,导致结果不一致或性能问题。
❌ 1、低效表达式(RAND() 在表达式中多次使用):
-- 错误:RAND() 每次调用返回不同值
SELECT
id,
RAND() AS r,
CASE WHEN RAND() > 0.5 THEN 'A' ELSE 'B' END AS group_name
FROM users;
-- 同一行中 RAND() 调用两次,结果可能不一致
✅ 2、优化表达式(使用 CTE 或变量缓存随机值):
WITH random_users AS (
SELECT
id,
RAND() AS r -- 只生成一次
FROM users
)
SELECT
id,
r,
CASE WHEN r > 0.5 THEN 'A' ELSE 'B' END AS group_name
FROM random_users;
优势:
十九、利用布尔代数化简复杂条件表达式
多个 AND/OR/NOT 组合的条件表达式可能包含冗余逻辑,我们可通过布尔代数(如:德摩根律、吸收律)进行化简,减少判断次数。
❌ 1、低效表达式(逻辑冗余):
SELECT *
FROM orders
WHERE (status = 'shipped' OR status = 'delivered')
AND (status = 'shipped' OR payment_status = 'paid');
-- 存在重复判断,逻辑复杂
分析: 设 A = status = 'shipped', B = status = 'delivered', C = payment_status = 'paid'原表达式:(A ∨ B) ∧ (A ∨ C)根据布尔代数分配律:A ∨ (B ∧ C)
✅ 2、优化表达式(化简后逻辑等价):
SELECT *
FROM orders
WHERE status = 'shipped'
OR (status = 'delivered' AND payment_status = 'paid');
优势:
- 更清晰表达业务逻辑:“已发货” 或 “已交付且已支付”;
- 在短路求值下,
status = 'shipped' 成立时直接跳过后续判断。
建议:对复杂风控、权限判断等场景,可借助工具或手动进行布尔化简。
二十、避免浮点精度问题在算术表达式中的传播
FLOAT/DOUBLE 类型存在精度误差,直接用于比较或累积计算会导致错误结果。
❌ 1、低效表达式(浮点比较):
-- 由于精度问题,0.1 + 0.2 ≠ 0.3
SELECT *
FROM transactions
WHERE amount = 0.3; -- 可能无法匹配实际值为 0.30000000000000004 的记录
✅ 2、优化表达式(使用 DECIMAL 或容忍误差):
-- 方法一:使用精确数值类型(推荐)
ALTER TABLE transactions
MODIFY COLUMN amount DECIMAL(10,2); -- 精确到分
SELECT * FROM transactions WHERE amount = 0.30;
-- 方法二:使用容忍误差的比较(适用于无法修改类型)
SELECT *
FROM transactions
WHERE ABS(amount - 0.3) < 0.0001; -- 容忍 1e-4 误差
优势:
通用规则:金额、税率、权重等关键数值,必须使用DECIMAL而非FLOAT。
二十一、利用表达式统计信息指导优化决策
数据库优化器依赖统计信息(Statistics)估算行数。若表达式涉及的列无统计信息,可能导致错误的执行计划。
❌ 1、低效表达式(统计信息缺失):
-- created_at 有索引,但未收集函数表达式的统计
SELECT * FROM logs
WHERE DATE(created_at) = '2023-01-01';
-- 优化器无法准确估算 DATE(created_at) 的分布,可能选择全表扫描
✅ 2、优化表达式(收集表达式统计信息):
-- PostgreSQL:为表达式收集统计信息
CREATE STATISTICS IF NOT EXISTS logs_date_stats
ON (DATE(created_at)) FROM logs;
ANALYZE logs; -- 更新统计
-- 优化器现在能更好估算行数,可能选择索引扫描
SELECT * FROM logs WHERE DATE(created_at) = '2023-01-01';
优势:
- 尤其适用于
WHERE FUNCTION(col) = value 场景。
适用数据库:PostgreSQL 10+、Oracle(扩展统计)、SQL Server(统计信息)。
二十二、在分布式数据库中优化跨节点表达式执行
在 TiDB、Greenplum、ClickHouse 集群 等分布式数据库中,表达式若涉及跨节点数据,可能导致大量数据传输。
❌ 1、低效表达式(表达式导致数据重分布):
-- Greenplum 示例:users 按 id 分布,orders 按 order_id 分布
SELECT
u.name,
SUM(o.amount * 1.1) AS total_with_tax
FROM users u
JOIN orders o ON u.id = o.user_id
GROUP BY u.name;
-- 若 join 键与分布键不一致,需重分布数据,开销巨大
✅ 2、优化表达式(将计算下推到数据本地):
-- 先在本地聚合,减少传输量
WITH local_agg AS (
SELECT
user_id,
SUM(amount * 1.1) AS local_total -- 在每个节点本地计算
FROM orders
GROUP BY user_id
)
SELECT
u.name,
SUM(la.local_total) AS total_with_tax
FROM users u
JOIN local_agg la ON u.id = la.user_id
GROUP BY u.name;
优势:
二十三、利用函数确定性(Deterministic)提升缓存与物化效率
数据库可对确定性函数(Deterministic Function)的结果进行缓存或物化。若自定义函数未声明为 DETERMINISTIC,则优化器无法优化。
❌ 1、低效表达式(未声明确定性):
-- MySQL:自定义函数未声明 DETERMINISTIC
DELIMITER $$
CREATE FUNCTION calc_discount(price DECIMAL, level INT)
RETURNS DECIMAL
READS SQL DATA -- 默认,表示可能读数据,非确定性
BEGIN
RETURN price * CASE
WHEN level = 1 THEN 0.9
WHEN level = 2 THEN 0.8
ELSE 1.0
END;
END$$
问题:优化器无法缓存 calc_discount(price, level) 结果,每行都调用。
✅ 2、优化表达式(声明为 DETERMINISTIC):
DELIMITER $$
CREATE FUNCTION calc_discount(price DECIMAL, level INT)
RETURNS DECIMAL
DETERMINISTIC -- 声明:相同输入必得相同输出
BEGIN
RETURN price * CASE
WHEN level = 1 THEN 0.9
WHEN level = 2 THEN 0.8
ELSE 1.0
END;
END$$
优势:
注意:仅当函数无副作用、不读数据库、不依赖会话变量时才可声明为 DETERMINISTIC。
二十四、使用 SQL 宏(SQL Macros)或模板统一高频表达式
多个 SQL 中重复使用相同复杂表达式(如:“用户生命周期价值”),易出错且难维护。
❌ 1、低效表达式(重复代码):
-- 报表 A
SELECT user_id, revenue * 0.7 - cost * 1.2 AS ltv FROM user_stats;
-- 报表 B
SELECT user_id, revenue * 0.7 - cost * 1.2 AS ltv FROM user_history;
-- 表达式重复,修改需多处同步
✅ 2、优化表达式(使用 SQL 宏或模板):
方式一:数据库原生宏(Oracle SQL Macros)
-- Oracle 21c+
CREATE FUNCTION compute_ltv(rev NUMBER, cost NUMBER)
RETURN VARCHAR2 SQL_MACRO
IS
BEGIN
RETURN q'(rev * 0.7 - cost * 1.2)';
END;
/
-- "/",Oracle 工具中用于执行 PL/SQL 块的命令
-- 使用
SELECT user_id, compute_ltv(revenue, cost) AS ltv FROM user_stats;
-- 宏展开为:revenue * 0.7 - cost * 1.2
方式二:应用层模板(Jinja、MyBatis)
-- Jinja 模板
SELECT user_id, {{ ltv_formula('revenue', 'cost') }} AS ltv
FROM user_stats;
方式三:视图封装
CREATE VIEW user_ltv AS
SELECT
user_id,
revenue * 0.7 - cost * 1.2 AS ltv
FROM user_stats;
-- 查询
SELECT user_id, ltv FROM user_ltv;
优势:
二十五、利用向量长度感知表达式(Vector-Length Aware Expressions)提升列式执行效率
在 ClickHouse、Doris、Snowflake 等列式数据库中,数据以“向量块”(Vector Batch)处理。表达式的写法应尽量对齐向量长度,避免分支预测失败。
❌ 1、低效表达式(条件分支不规则,破坏 SIMD 流水线):
-- 假设 x 是一个大数组/列
SELECT
CASE
WHEN x % 2 = 0 THEN x * 2
ELSE x * 3 + 1
END AS result
FROM large_table;
问题:奇偶交替导致分支高度不可预测,CPU 分支预测失败率高,破坏 SIMD 并行性。
✅ 2、优化表达式(使用向量化友好的算术组合):
-- 利用布尔向量作为掩码
SELECT
x * (2 + (x % 2)) + (x % 2) -- 等价于:偶数 *2,奇数 *3+1
-- 分解:偶数 → x*2 + 0;奇数 → x*3 + 1
FROM large_table;
优势:
小贴士:在列式引擎中,能用算术解决的,就不用分支。
二十六、避免表达式副作用(Expression Side Effects)破坏查询等价性
某些“看似无害”的表达式可能产生副作用(如:日志、计数器递增),导致查询重写、物化、缓存失效。
❌ 1、危险表达式(函数有副作用):
-- 自定义函数:记录调用次数(危险!)
CREATE OR REPLACE FUNCTION debug_log(val INT)
RETURNS INT AS $$
BEGIN
INSERT INTO debug_log_table VALUES (val, NOW()); -- 副作用!
RETURN val;
END;
$$ LANGUAGE plpgsql;
-- 使用
SELECT debug_log(id) FROM users WHERE id < 10;
-- 若优化器重写查询(如:谓词下推、并行扫描),日志可能被调用多次!
问题:数据库优化器假设函数无副作用,可能:
- 重排执行顺序; 导致日志重复、计数不准、业务逻辑错乱。
✅ 2、优化表达式(分离计算与副作用):
-- 计算阶段
WITH computed AS (
SELECT id FROM users WHERE id < 10
)
-- 副作用阶段(显式控制)
INSERT INTO final_result SELECT id FROM computed;
-- 日志单独记录
INSERT INTO audit_log SELECT 'query_executed', COUNT(*) FROM computed;
原则:SQL 表达式应是纯函数(Pure Function)——相同输入,永远相同输出,且无副作用。
二十七、使用表达式哈希(Expression Hashing) 加速去重与连接
当需要对复杂表达式结果去重或连接时,直接比较成本高,我们可预先计算哈希值。
❌ 1、低效表达式(直接比较复杂表达式):
-- 两个子查询基于复杂表达式连接
SELECT *
FROM (
SELECT CONCAT(first_name, ' ', last_name) AS full_name, ...
) a
JOIN (
SELECT CONCAT(fname, ' ', lname) AS full_name, ...
) b
ON a.full_name = b.full_name; -- 字符串逐字符比较,慢
✅ 2、优化表达式(使用表达式哈希):
-- 预计算哈希
WITH a_hashed AS (
SELECT
*,
city_hash_64(CONCAT(first_name, ' ', last_name)) AS name_hash
FROM table_a
),
b_hashed AS (
SELECT
*,
city_hash_64(CONCAT(fname, ' ', lname)) AS name_hash
FROM table_b
)
SELECT *
FROM a_hashed a
JOIN b_hashed b ON a.name_hash = b.name_hash
WHERE CONCAT(a.first_name, ' ', a.last_name) = CONCAT(b.fname, ' ', b.lname); -- 二次校验防碰撞
优势:
⚠️ 注意:需处理哈希碰撞,必要时二次校验。
二十八、利用编译型 SQL 引擎(如:WebAssembly)优化表达式执行
现代数据库(如:DuckDB、Materialize)开始支持将 SQL 表达式编译为 WASM 或本地机器码,跳过解释执行。
❌ 1、传统表达式(解释执行):
SELECT
sqrt(x*x + y*y) + log(z + 1) * scale_factor
FROM vectors;
-- 每行调用解释器解析函数调用
✅ 2、编译优化表达式(WASM JIT 编译):
-- DuckDB 示例:启用 WASM 扩展
INSTALL wasmtime;
LOAD wasmtime;
-- 将表达式编译为 WASM 模块(伪代码)
CREATE FUNCTION fast_vector_norm(x DOUBLE, y DOUBLE, z DOUBLE, s DOUBLE)
RETURNS DOUBLE
LANGUAGE wasm AS
'(func (param f64 f64 f64 f64) (result f64)
(f64.add
(f64.sqrt (f64.add (f64.mul (local.get 0) (local.get 0))
(f64.mul (local.get 1) (local.get 1))))
(f64.mul (f64.log (f64.add (local.get 2) (f64.const 1.0)))
(local.get 3))))';
优势:
未来方向:SQL 表达式将从“声明式”走向“编译式”。
二十九、使用语义等价重写(Semantic Rewriting)突破语法限制
某些表达式受语法限制无法使用索引,但可通过数学或逻辑等价变换实现优化。
❌ 1、无法索引的表达式(模运算):
SELECT * FROM users WHERE id % 2 = 0; -- 无法使用 id 索引
✅ 2、语义等价重写(转换为范围查询):
-- 若 id 连续或可预测
SELECT * FROM users WHERE id IN (
SELECT 2 * n FROM generate_series(1, 1000000) AS n
);
-- 或分区表中按 id%2 分区,直接定位分区
3、更强示例:将 LIKE '%suffix' 转换为反向索引
-- 创建反向字段
ALTER TABLE products ADD COLUMN name_reversed TEXT AS (REVERSE(name)) STORED;
CREATE INDEX idx_name_rev ON products(name_reversed);
-- 查询后缀
SELECT * FROM products WHERE name_reversed LIKE REVERSE('phone%');
-- 即 name_reversed LIKE '%enohp' → 可走索引
小贴士:不要被原始表达式束缚,思考其语义等价形式。
三十、SQL 表达式优化哲学:延迟计算,直到最后一刻
最优的表达式,往往是不存在的表达式。我们应追求:将计算尽可能推迟到数据消费端。
1、策略对比:
✅ 2、推荐实践:分层计算策略
# 应用层:只取必要字段
query = "SELECT price, qty, tax_rate FROM orders WHERE status = 'paid'"
# 客户端:计算最终金额
for row in cursor.fetchall():
final_price = row.price * row.qty * (1 + row.tax_rate)
display(final_price)
优势:
原则:
数据库擅长“找数据”,应用擅长“算数据”。
不要把 SQL 当作通用编程语言。
三十一、利用 AI 驱动的表达式重写引擎(AI-Powered Rewrite)
数据库开始集成 AI 模型,自动识别低效表达式并生成等价优化版本。
1、场景示例:
-- 用户写下:
SELECT * FROM logs
WHERE SUBSTR(message, 1, 3) = 'ERR' AND LENGTH(message) > 10;
-- AI 重写为:
SELECT * FROM logs
WHERE message LIKE 'ERR%' AND CHAR_LENGTH(message) > 10;
-- 可能进一步建议:在 message 上创建 ngram 索引
2、实现方式:
- 向量嵌入:将 SQL 表达式编码为向量,匹配已知优化模式;
- 强化学习:在执行反馈(如:执行时间)指导下,迭代优化重写策略;
- 大模型微调:使用 SQL 优化语料训练专用模型(如:SQL-Optimize-GPT)。
代表系统:
- Oracle Autonomous Database 的 AI 优化建议
- Microsoft SQL Server 的 Query Store + AI 反馈
- 开源项目如:SQLGlot 已支持自动表达式标准化
小贴士:你不再需要记住所有优化规则——让 AI 成为你的“外脑”。
三十二、构建表达式知识图谱(Expression Knowledge Graph)
组织内存在大量重复、不一致、甚至错误的 SQL 表达式。如何统一管理?
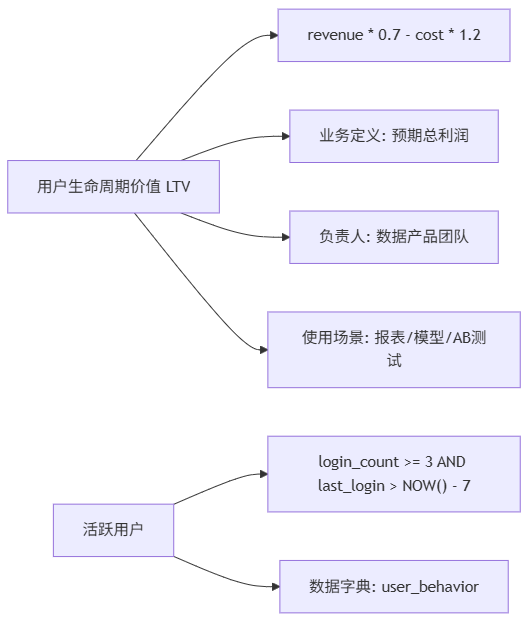
1、解决方案:建立“表达式知识图谱”
graph LR
A[用户生命周期价值 LTV] --> B[revenue * 0.7 - cost * 1.2]
A --> C[业务定义: 预期总利润]
A --> D[负责人: 数据产品团队]
A --> E[使用场景: 报表/模型/AB测试]
F[活跃用户] --> G[login_count >= 3 AND last_login > NOW() - 7]
F --> H[数据字典: user_behavior]
2、实现方式:
- 使用 Data Catalog(如:Atlas、DataHub)标注高频表达式;
优势:
未来形态:SQL 表达式将成为可复用的“语义资产”。
三十三、使用物化表达式服务(Materialized Expression Service)
多个系统需要相同计算逻辑(如:“用户等级”),在各处重复计算。
1、传统做法:
✅ 2、优化架构:独立的表达式计算服务
+----------------+ +---------------------+ +--------------+
| 用户服务 | --> | 表达式服务 API | --> | 返回 user_level |
| (user_id=123) | | /v1/eval/user_level | | = 'VIP' |
+----------------+ +---------------------+ +--------------+
3、实现方式:
优势:
理念:表达式不应绑定于 SQL,而应作为独立的“计算单元”。
三十四、在流式 SQL(Streaming SQL)中优化表达式状态管理
在 Flink、Spark Streaming、ksqlDB 中,表达式可能涉及状态(如:LAST_VALUE, SESSION_GAP),管理不当会导致内存爆炸。
❌ 1、低效表达式(未限制状态):
-- Flink SQL
SELECT
user_id,
LAST_VALUE(page) OVER (
PARTITION BY user_id
ORDER BY ts
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS last_page
FROM user_events;
-- 状态无限增长!
✅ 2、优化表达式(限制状态保留时间):
-- 启用状态TTL
SET 'state.ttl' = '1h';
-- 或使用有限窗口
SELECT
user_id,
LAST_VALUE(page) OVER (
PARTITION BY user_id
ORDER BY ts
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW
) AS last_page
FROM user_events;
原则:流式表达式必须考虑“时间边界”与“状态成本”。
三十五、利用零拷贝表达式执行(Zero-Copy Expression Evaluation)
硬件级优化:现代数据库(如:DuckDB、ClickHouse)采用“向量化执行 + 零拷贝”架构。
1、核心思想:
2、示例:
-- 表达式:a + b * c
-- 传统:先计算 b*c → 临时向量 T1 → a + T1 → 结果
-- 零拷贝:循环中直接计算 a[i] + b[i]*c[i] → 结果[i]
3、优化建议:
性能差异:可达 10 倍以上。
三十六、终极答案:删除表达式
最高境界:最快的表达式,是不存在的表达式;最优的计算,是不需要计算的计算。
1、实现方式:
| |
|---|
| 预计算 | |
| 缓存 | 使用 Redis/Memcached 缓存复杂表达式结果 |
| 物化视图 | |
| 事件驱动更新 | |
2、示例:
-- 不要实时计算“用户总消费”
-- 而是在每次订单完成时:
UPDATE user_summary
SET total_spent = total_spent + :amount
WHERE user_id = :user_id;
-- 查询时直接读:
SELECT total_spent FROM user_summary WHERE user_id = 123;
原则:
实时计算是成本,预计算是投资。
当“读远多于写”时,预计算永远是最优解。
结语:优化的终点是“无为”
我们一路走来:
- 从
WHERE YEAR(create_time) = 2023 到 create_time BETWEEN '2023-01-01' AND '2023-12-31'
附录:SQL 表达式基础优化检查清单(Final Checklist)
在编写或审查 SQL 表达式 时,请逐项确认:
1、[ ] 是否存在重复计算?→ 用 CTE 或变量缓存
2、[ ] 是否在索引列上使用函数?→ 改写为列与常量比较
3、[ ] 是否有隐式类型转换?→ 确保类型一致
4、[ ] 是否使用了标量子查询?→ 用窗口函数或 JOIN 替代
5、[ ] 是否有 NULL 参与运算?→ 使用 COALESCE 或 NULLIF
6、[ ] 是否频繁解析 JSON?→ 使用生成列 + 索引
7、[ ] 是否可用布尔表达式替代 CASE WHEN?→ 提升执行效率
8、[ ] 日期计算是否可参数化?→ 避免运行时函数调用
9、[ ] 复杂表达式是否可物化?→ 使用生成列
10、[ ] 是否适用于列式数据库?→ 优先使用向量化友好函数
11、[ ] 是否使用了随机函数?→ 确保一致性,避免重复调用
12、[ ] 是否可通过表达式索引加速?→ 创建 FUNCTIONAL INDEX
该文章在 2025/8/19 12:17:07 编辑过






 400 186 1886
400 186 1886


